LLM IEM Rearranger?
I was watching and reading about how a transformer model actually works, and it’s really fascinating. Then I thought — if it’s really just predicting the next token, wouldn’t it be really good at being a 中文输入法, a Chinese IME? Fun fact: that was the first time I realized I had no clue what 输入法 is called in English.
After some research — and by “research” I mean prompting back and forth with an AI, with some manual validation of its responses — I decided to go with a reranking approach.
The problem
Here’s what I want the IME to do. Say the user is typing a long passage like:
可是夫人ta又怎么会知道,ta的大儿子早已经毕业了,还生了个可爱的小女孩,叫张婷. 张婷很可爱,邻居们天天总在说:“看看那个小女孩,和ta爸长得真像” 大儿子叫张三,虽然毕业没多久但头发已经秃了不少,不少街坊领居都说,ta是在用头发讨生活。
A normal IME ranks candidate characters by frequency — 他 tends to outrank 她 simply because it appears more often overall. So when the user types ta, the IME might prompt:
1.他 2.她 3.塔 4.它 5.塌 6.踏 7.嗒 ...
In this case, the correct option (她) ends up at no. 2 purely because no. 1 appears more frequently in the corpus — context be damned.
Something worth mentioning
Before landing on the rerank approach, I actually thought about using an LLM as the engine itself. The overall flow would have looked something like:
User types pinyin → LLM reads the pinyin + the context → LLM generates results → the “IME” parses them and lets the user select
It sounds like a fever dream, honestly. This kind of approach totally bypasses a traditional IME, but it’s also prone to hallucination, and really what it would be doing is generating a distribution over a super-abstract pinyin input — which isn’t what it was trained for. I think even at the tokenizer stage, after the first embedding layer, it would already have a hard time following the context of what’s going on.
But I still tried it anyway, and the result was absolutely awful, so I scrapped it. One day maybe, one day.
The idea (frfr)
So if we can plug an LLM into this step — one that actually reads and understands the surrounding context — perhaps we can rearrange the candidates. Using the same passage:
可是夫人ta又怎么会知道,ta的大儿子早已经毕业了,还生了个可爱的小女孩,叫张婷. 张婷很可爱,邻居们天天总在说:“看看那个小女孩,和ta爸长得真像” 大儿子叫张三,虽然毕业没多久但头发已经秃了不少,不少街坊领居都说,ta是在用头发讨生活。
The model should somehow be able to correlate the vectors of 张婷 with a region representing the female gender, so when the user types ta, it would rerank the candidates to:
1.她 2.他 3.塔 4.它 5.塌 6.踏 7.嗒 ...
The screenshot below shows that even starting from 夫人 (which means “madam”), the LLM can rerank the following ta to the correct 她.
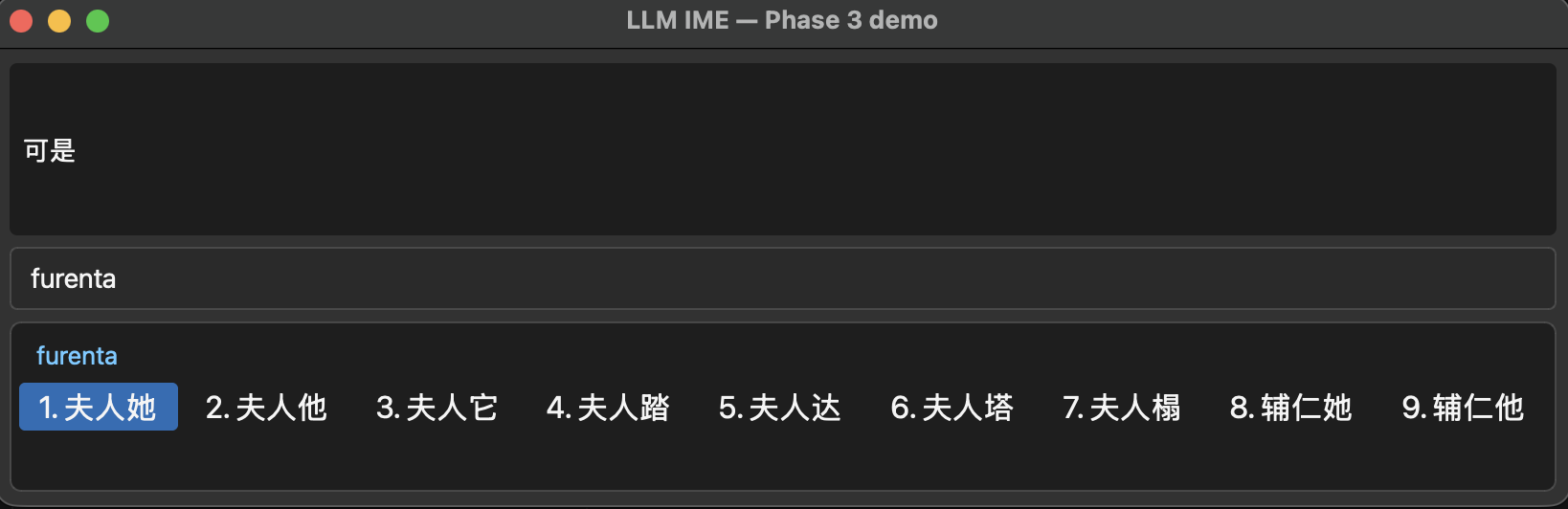
This case shows more clearly how an LLM-powered IME can use context to its advantage — which is genuinely useful when you’re typing, since all you really do is mash keys and smack that space bar.
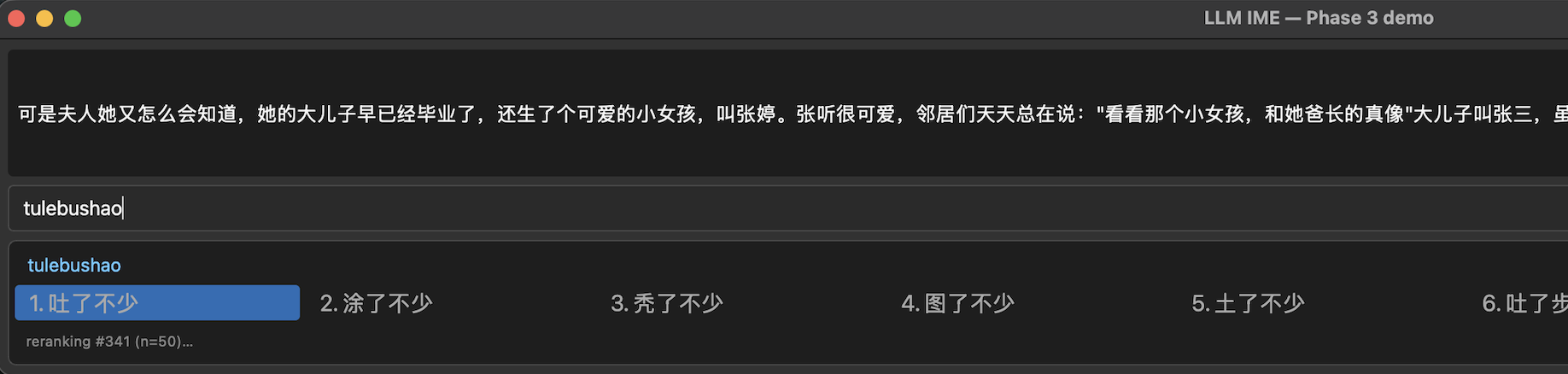
Before
After
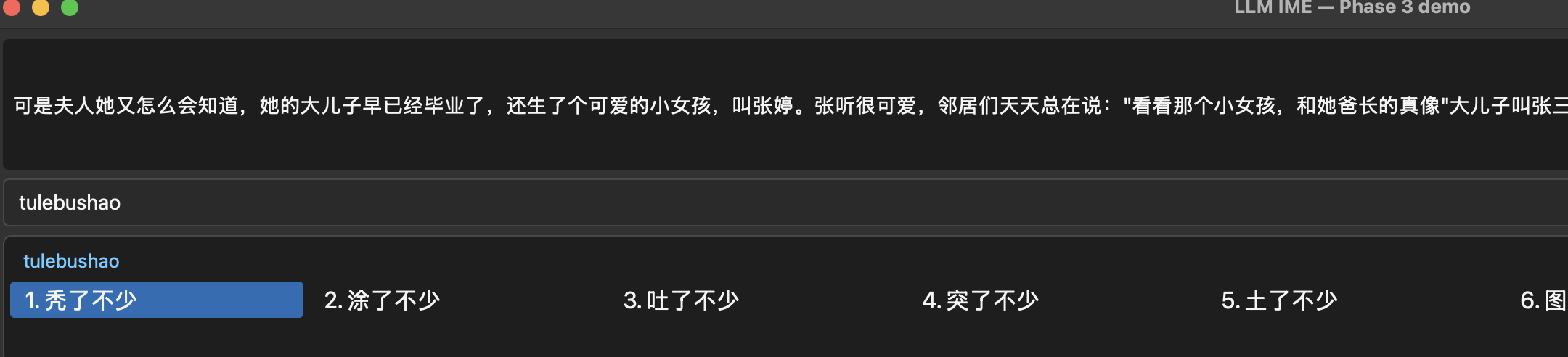
It nicely showcases the model picking balding when the context is about hair, instead of the original IME’s default throwing up.